Article
What is incident management? Types and solutions explained
Discover proven frameworks to identify, respond to, and prevent IT disruptions while building a stronger, more resilient IT team.


Mozhdeh Rastegar-Panah
Senior Director, Product Marketing
최종 업데이트: August 26, 2025


What is incident management?Incident management is a structured approach to responding to unplanned disruptions or degradations of IT services, with the goal of restoring normal operations as quickly as possible. Effective incident management includes:
It encompasses the processes, roles, and tools used to identify, analyze, and resolve technical issues while minimizing impact on business operations and customers. |
It’s an all-too-common scenario: your team is nearing the end of a time-consuming product rollout when your core service crashes. Customers can’t log in, internal teams are blocked, and everyone is looking for answers. Incident management is how companies fix these worst-case scenarios.
Incident management is the structured process of identifying, assessing, and resolving IT service disruptions. It applies to everything from a sluggish application to a complete outage. In IT service management (ITSM), this discipline isn’t just about quick fixes. It’s a foundation for operational stability that can make or break customer trust.
Explore all the key aspects of a reliable incident management system, like best practices and must-measure help desk metrics to improve incident management, below.
More in this guide:
- Why is incident management crucial for effective service?
- Types of incident management
- 6 steps of the incident management framework
- Best practices for comprehensive incident management
- Tools and automation for incident management
- Key metrics to track incident management effectiveness
- Frequently asked questions
- Resolve incidents faster with Zendesk
Why is incident management crucial for effective service?
When something breaks, every second counts. Whether it’s a login issue that prevents employees from working or a glitch that frustrates customers, speed and clarity are essential.
Strong incident management allows teams to take control of the situation, restore service quickly, and maintain a high quality of customer service, even under pressure. But the benefits extend far beyond just fixing things when they break. Here are some of the top benefits you can expect from a great incident management solution:
Incident management function | Why it’s important |
Business continuity and revenue protection | For digital customer service businesses, downtime means lost revenue. Strong incident management is crucial for quickly containing disruptions, especially for e-commerce and SaaS, which need 24/7 availability. |
Customer experience and retention | Incident handling impacts customer perception. If you handle situations transparently and resolve them quickly, customers will forgive occasional technical issues. Effective incident management communicates status, timelines, and follow-up. |
Employee productivity and morale | Internal IT incidents don’t just frustrate employees. They can completely derail productivity. When tools and applications fail, teams become idle. Incident management restores operations quickly and keeps employees focused on their responsibilities. |
Regulatory compliance and risk management | Strict regulations in industries like healthcare, finance, and government mandate specific response times and documentation for service availability and incident response. Structured incident management helps organizations meet these, reducing penalty and compliance violation risks. |
Learning and improvement opportunities | Incidents offer learning opportunities. Mature incident management includes post-incident reviews for continuous improvement, preventing future issues, and building resilient systems. |
Types of incident management
 |
Incident management takes different forms depending on how an organization operates. Here’s a breakdown of the most common models:
A traditional help desk approach, ITSM incident management uses structured ticketing systems and processes to handle service disruptions. It involves detailed documentation, approval workflows, and structured escalation procedures, making it effective for organizations with complex compliance needs or large IT infrastructures. | |
DevOps incident management | A swift, collaborative model for DevOps teams, emphasizing real-time monitoring and automation for system stability. This approach prioritizes rapid response and learning from failures, often through blameless post-mortems, automated alerts, and self-healing systems. It sacrifices some formality for speed, so it has shorter response times. |
Major incident management | A high-level response model for widespread issues impacting many users or critical business operations, often requiring cross-team coordination. It involves specialized communication that’s activated when normal processes are insufficient. It includes executive briefings, customer communication, and post-incident business impact assessments. |
Business continuity incident management | An aspect of disaster recovery, this model handles events like cyberattacks, natural disasters, or system failures. It encompasses IT, business operations, HR, and external stakeholders. It includes alternate work locations and backup communications to ensure essential business functions continue despite primary system unavailability. |
Each approach has its strengths and is suited to different organizational needs. Many companies use a hybrid model, applying different incident management types based on the severity and scope of each incident.
6 steps of the incident management framework
Incident response typically follows a repeatable structure. Here’s how teams handle incidents from start to finish.
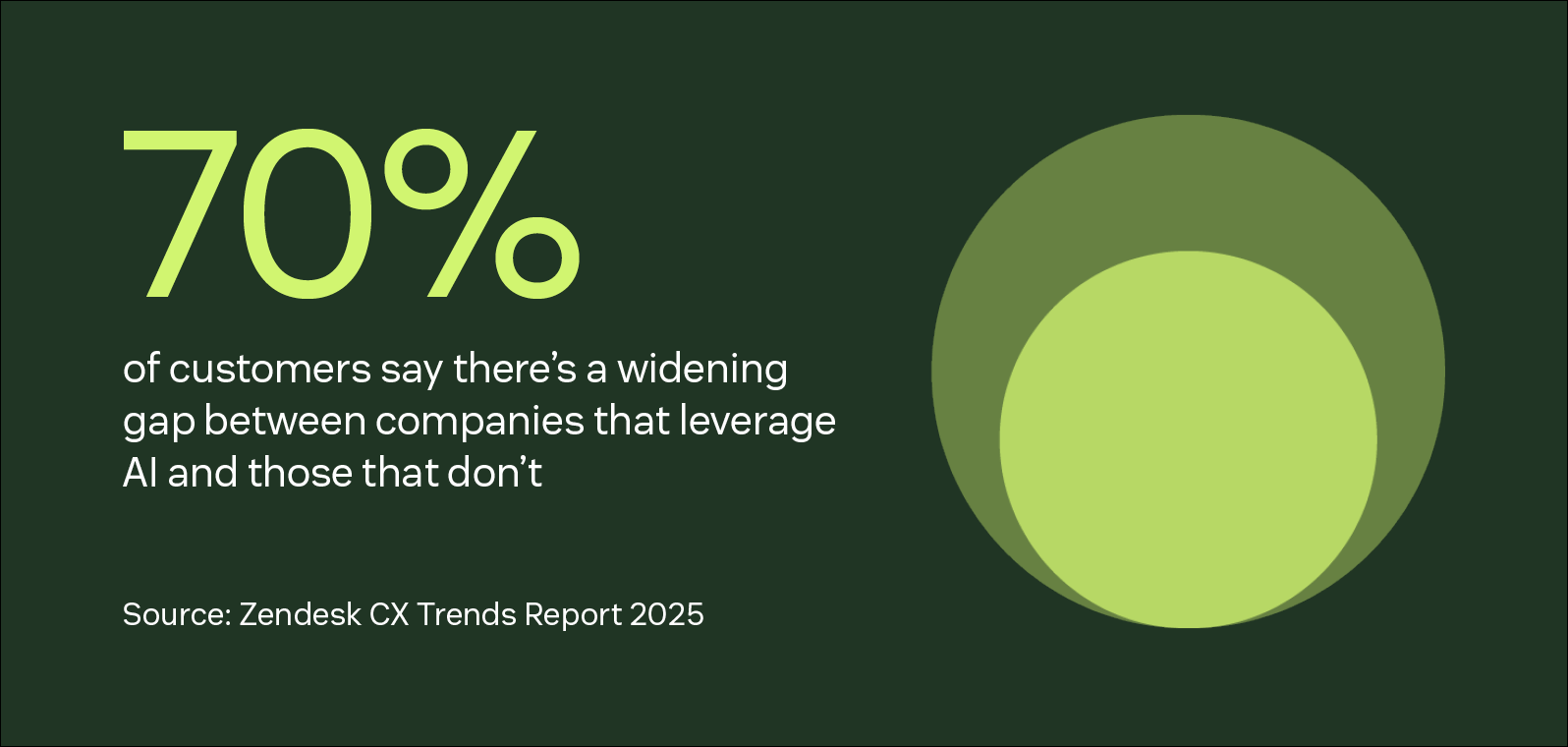
1. Detect and identify
Issues are often detected via monitoring tools or support tickets. Solutions like Zendesk use AI to analyze all tickets and interactions to catch issues before they develop into larger problems.
 |
Early detection is crucial to minimizing an issue’s impact, with steps like:
AI or automated system monitoring
User reports
Synthetic transaction monitoring
Proactive health checks
AI and machine learning also identify anomalies and predict potential issues in real time, allowing teams to proactively work on a solution.
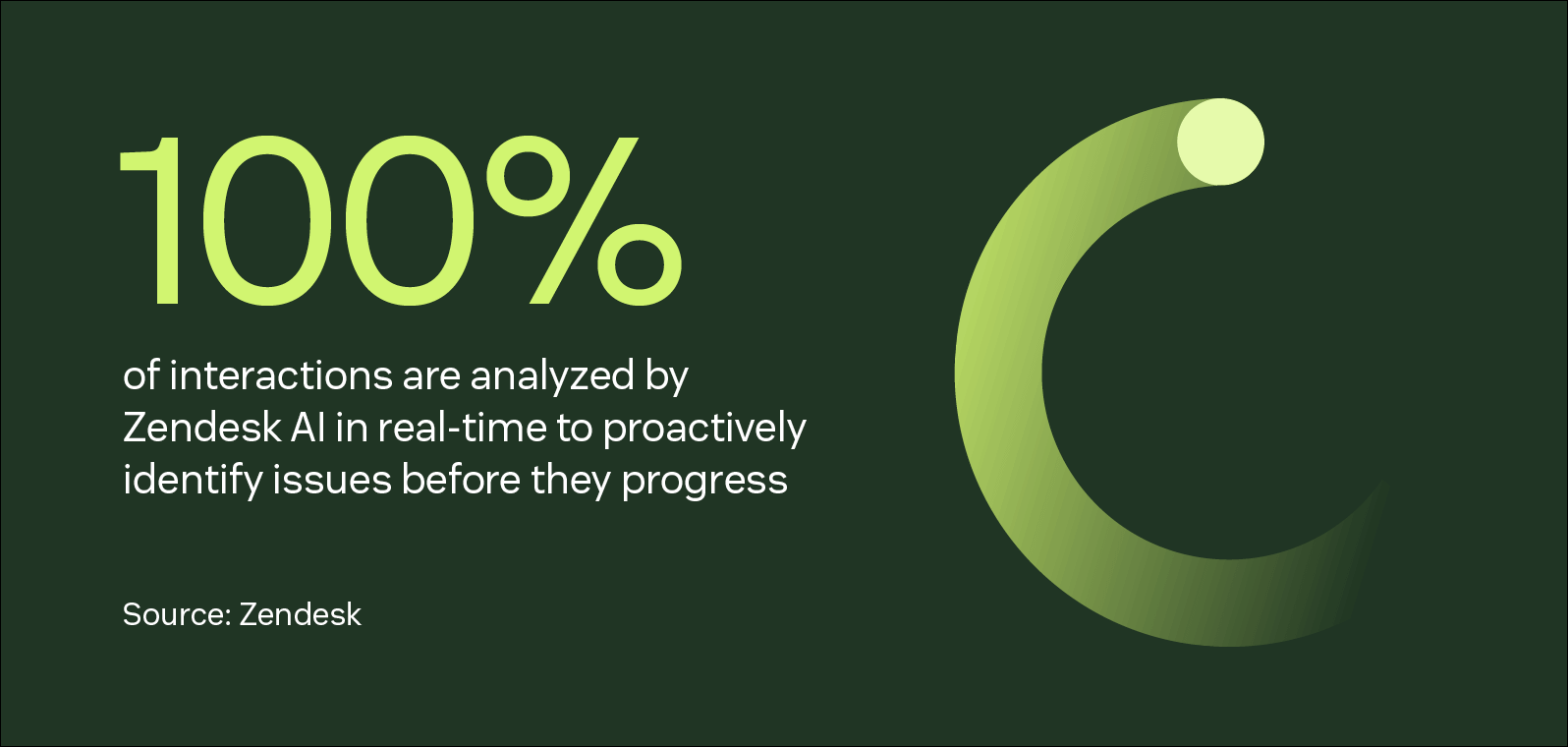
2. Record and classify
Incidents are logged and classified by severity, urgency, and impact to prioritize tasks and allocate resources. Classification considers things like the most affected:
Users
Overall business functions
Financial impact
Priority levels (P1–P4) and severity categories (Critical–Low) are common ways of labeling these classifications. Accurate classification determines response times, escalation, and more, and has standardized criteria for consistency across issues.
 |
AI-powered systems can automatically classify incidents based on historical data and content analysis, reducing human error and speeding up the initial response. AI agents, for example, are intelligent bots that can analyze ticket content and assign appropriate priority levels instantly.
3. Dig deeper and diagnose
Teams analyze the problem by reviewing system logs and error messages to determine the root cause. This investigative phase often involves multiple team members with different areas of expertise.
Diagnosis techniques include:
Log analysis
System performance monitoring
Database queries
Recreating the problem in test environments
For effective diagnosis, you need both technical skills and access to comprehensive data. AI-powered incident management software constantly gathers data to give the clearest possible insights into issues and possible diagnoses.
4. Escalate
Complex issues or those outside the team’s expertise are escalated to specialized groups or external vendors.
Escalation should be swift to avoid delays, triggered by exceeding response time, or needing restricted system access or vendor support. Effective escalation requires clear handoff, complete documentation, and continued monitoring by the original responder.
5. Resolve and recover
After identifying the cause, the team applies a solution and restores services, communicating progress to affected users. Resolution might involve
Patches
Restarts
Rollbacks
Workarounds
Overall, the resolution focuses on rapid restoration and minimal disruption. Recovery includes verifying the fix and monitoring systems to prevent recurrence.
6. Close and review
Following the resolution, teams conduct a post-incident review to document the event, noting successes and areas for improvement.
This timely review covers:
Timeline analysis
Root cause
Process effectiveness
Recommendations
It creates valuable organizational knowledge to prevent future incidents and enhance response.
Best practices for comprehensive incident management
High-performing teams follow a few best practices to keep their incident response efficient and resilient:
- Prepare your team in advance: Clarify roles, conduct regular training, and document procedures. Just like in fire departments, regular drills reduce response time and stress during incidents.
- Maintain clear communication: Communication during an incident should be timely and consistent—even if you don’t yet have a fix—because regular updates help build trust with users. Use status pages, email, and social media for external updates. Internally, establish dedicated channels for response, clear escalation, and regular leadership updates.
- Document effective responses: Document in playbooks and runbooks to help teams act fast and stay aligned during high-pressure situations. These should include step-by-step procedures, contacts, system access details, and troubleshooting guides for the most consistent response quality.
- Conduct thorough post-incident reviews: All incidents need a post-review to pinpoint improvements and lessons learned. Focus on the process, not blame. Effective reviews identify systemic issues, resulting in clear action items to resolve them.
- Implement continuous improvement: Analyze incident data to spot patterns and systemic issues. This data-driven approach builds more resilient systems by revealing recurring problems and gaps.
While strong processes and practices form the foundation of effective incident management, having the right tools can distinguish between a chaotic response and a coordinated resolution.
Tools and automation for incident management
Equip your team with the right tools for a significant improvement in how you manage and resolve incidents:
- Incident response platforms: These platforms bring all alerts and action items into one place, making it easier to assign tasks and monitor the progress of an incident from start to finish.
- Monitoring and alerting tools: Proactively scan your systems for signs of trouble and send alerts so your team can respond before users even notice a problem.
- Communication and collaboration software: Systems like Slack or Microsoft Teams allow teams to work together in real time and eliminate the confusion that often slows response.
- Status page systems: These systemshelp you keep internal teams and external users informed with live updates about outages or service changes.
- On-call management solutions: This takes the guesswork out of who’s available by scheduling and rotating staff, ensuring someone is always ready to respond.
- Runbooks and documentation systems: These offer pre-written, step-by-step instructions that even new team members can follow during a high-stakes incident.
- Post-mortem and analytics tools: After an incident, look to AI-powered customer service reports with real-time analytics to identify trends, predict future incident types, and provide actionable insights for process improvement.
- Automation and orchestration platforms: Speed up response time by executing pre-set tasks, rerouting traffic, or launching scripts without manual intervention.
- Help desks and service desks: Keep your incidents organized by logging issues, assigning them to the right people, and tracking them through to resolution.
- Root cause analysis software: Identify the deeper issues behind recurring incidents so you can fix the problem at its source, not just the symptoms.
The right combination of tools can transform your incident response from reactive firefighting to proactive problem-solving, but success ultimately depends on how well you measure and optimize your performance.
Key metrics to track incident management effectiveness
Tracking the right performance metrics helps teams optimize their approach and prove the value of incident management:
- Mean time to detect (MTTD) measures how quickly your team becomes aware of a problem after it begins.
- Mean time to respond (MTTR) calculates the average time your team takes to address the issue once it’s identified.
- First contact resolution (FCR) rate shows how often your team can fix problems on the first attempt without escalating.
- Incident volume tracks the number of incidents over a given period, which can help you identify new risks or system instability.
- Incident recurrence rate reveals whether similar issues keep reappearing, suggesting that root causes may still need attention.
- Customer satisfaction (CSAT)reflects how users feel about the resolution process, often gathered through post-incident surveys.
- Service level agreement (SLA) compliance rate measures how consistently your team meets the response and resolution timelines promised to users or clients.
Tracking these metrics consistently can help you improve your incident response over time and be better equipped to answer common questions about your incident management approach.
Frequently asked questions
Customer story

The Wharton School
Zendesk Support's iPad app allows Wharton Computing's team to answer tickets on the go
"Zendesk Support looks great and operates with ease. It allows us to work smarter and stay focused. My agents are happy."
- Sharon Steptoe-Smith
IT Administrative Coordinator
Resolve incidents faster with Zendesk
The stakes are high: IT downtimes are prohibitively expensive for companies of any size and can damage brand reputation in the long term. When executed well, incident management helps reduce downtime, keeps costs in check, and maintains trust among employees and customers.
When issues arise, Zendesk incident management software gives your team the structure and tools to act fast, stay organized, and communicate clearly with everyone involved. From smart ticketing workflows to reporting and analytics, Zendesk helps you turn disruption into an opportunity to build trust.
Discover how Zendesk can help improve your incident management with a free trial today and witness how the right tools can transform your team’s response to IT disruptions.





